
What do hackers want? If you answered money — always a safe bet — then you’d be right. According to the Verizon Data Breach Investigations Report (DBIR), financial gain still is the motivation for over 75% of incidents it had investigated.
A better answer to the above question is that hackers want data — either monetizeable or sensitive content — that is scattered across large corporate file systems. These are the unencrypted user-generated files (internal documents, presentations, spreadsheets) that are part of the work environment. Or if not directly created by users, these files can be exported from structured databases containing customer accounts, financial data, sales projections, and more.
Get the Free Pentesting Active
Directory Environments e-book
Our demand for this data has grown enormously and so have our data storage assets. Almost 90% of the world’s data was created over the last 2 years alone, and by 2020 data will increase by 4,300% — that works out to lots of spreadsheets!
Challenges of data security
Unfortunately, the basic tools that IT admins use to manage corporate content – often those that are bundled with the operating systems — are not up to the task of finding and securing the data.
While you’ll need outside vendors to help protect your data assets, it doesn’t necessarily mean there’s been an agreement on the best way to do this. Sure you can try to lock the virtual doors through firewalls and intrusions systems — simply preventing anyone from getting in.
Or you can take a more realistic approach and assume the hackers will get in.
Security from the inside out
What we’ve learned over the last few years after a string of successful attacks against well-defended companies is that it’s impossible to build an intrusion-proof wall around your data.
Why?
Hackers are being invited in by employees–they enter in through the front door. The weapon of choice is phish mail: the attacker, pretending to represent a well-known brand (FedEx, UPS, Microsoft), sends an email to an employee containing a file attachment that appears to be an invoice or other business document
When employees click, they are in fact launching the malware payload, which is embedded in the attachment.
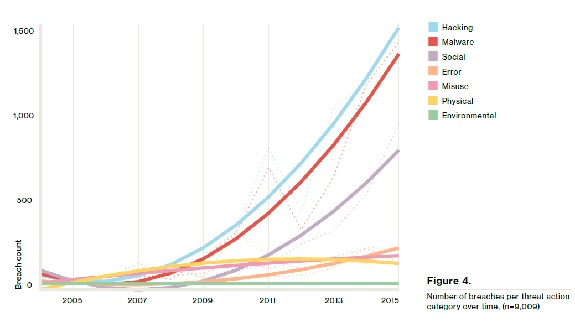
Verizon’s DBIR has been tracking real-world hacker attack techniques for years. Social engineering, which includes phishing as well as other pretexting methods. has been exploding (see graph).
What happens once they're in?
The DBIR team also points out that hackers can get in quickly (in just a few days or less). More often than not, IT security departments then take months to discover the attack and learn what was taken.
The secret to the hacker’s stealthiness once they gain a foot hold is that the use stealthy fully undetectable (FUD) malware. They can fly under the radar of virus scanners while collecting employee key strokes, probing file content, and then removing or exlfiltrating data.
Or if they don’t use a phishing attack to enter, they can find vulnerabilities in public facing web properties and exploit them using SQL injection and other techniques.
And finally, hackers have been quite good at guessing passwords due to poor password creation practices — they can simply log in as the employee.
Bottom line: the attackers enter and leave without triggering any alarms.
A strategy we recommend for real-world defense against this new breed of hackers is to focus on the sensitive data first and then work out your defenses and mitigations from that point — an approach known as “inside out security”.
Three steps to inside out security
Step one: Taking inventory of your IT infrastructure and data
Before you can create an inside out security mindset, a good first step is simply to take an inventory of your IT infrastructure.
It’s a requirement found in many data standards or best practices, such as ISO 27001, Center for Internet Security Critical Security Controls, NIST Critical Infrastructure Cybersecurity (CIS) Framework, or PCI DSS.
Many standards have controls that typically go under the name of asset management or asset categorization. The goal is to force you to first know what’s in your system: you can’t protect what you don’t know about!
Along with the usual hardware (routers, servers, laptops, file server, etc.), asset categorization must also account for the digital elements —important software, apps, OSes, and, of course, data or information assets.
For example, the US National Institute of Standards and Technology (NIST) has its Critical Infrastructure Cybersecurity Framework, which is a voluntary guideline for protecting IT of power plants, transportation, and other essential services. As with all frameworks, CIS provides an overall structure in which various specific standards are mapped.
The first part of this framework has an “Identify” component, which includes asset inventory subcategories — see ID.AM 1 -6 — and content categorization—see ID.RA-1 and ID.RA-2.
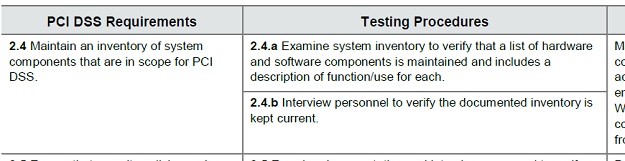
Or if you look at PCI DSS 3.x, there are controls to identify storage hardware and more specifically sensitive card holder data – see Requirement 2.4.
Step two: Reducing risk with access rights
Along with finding sensitive content, security standards and best practices have additional controls, usually under a risk assessment category, that ask you to look at the access rights of this data. The goal is to learn whether this sensitive data can be accessed by unauthorized users, and then to make adjustments to ensure that this doesn’t happen.
Again referring to the CIS Framework, there’s a “Protect” function that has sub-categories for access controls – see PR.AC-1 to PR.AC-4.
Specifically, there is a control for implementing least privilege access (AC.4), which is a way to limit authorized access by given minimum access rights based on job functions. It’s sometimes referred to as role-based access controls or RBAC.
You can find similar access controls in other standards as well.
The more important point is that you should (or it’s highly recommended) that you implement a continual process of looking at the data, determining risks, and making adjustments to access controls and taking other security measures. This is referred to as continual risk assessment.
Step three: Data minimization
In addition to identifying and limiting access, standards and best practices have additional controls to remove or archive PII and other sensitive data that’s no longer needed.
You can find this retention limit in PCI DSS 3.1 – “Keep cardholder data storage to a minimum” found in requirement 3. The new EU General Data Protection Regulation (GDPR), a law that covers consumer data in the EU zone, also calls for putting a time limit on storing consumer data — it’s mentioned in the key protection by design and default section (article 25).
Ideas for minimizing both data collection and retention as a way to reduce risk are also part of another best practice known as Privacy by Design, which is an important IT security guideline.
The hard part: Data categorization at scale
The first step, finding the relevant sensitive data and categorizing it, is easier said than done.
Traditionally, categorization of unstructured data has involved a brute force scanning of the relevant parts of the file system, matching against known patterns using regular expressions and other criteria, and then logging those files that match the patterns.
This process, of course, then has to be repeated — new files are being created all the time and old ones updated.
But a brute force approach would start completely from scratch for each scan — beginning at the first file in its list and continuing until the last file on the server is reached.
In other words, the scan doesn’t leverage any information from the last time it crawled through the file system. So if your file system has 10 million files, which have remained unchanged, and one new has been added since the last scan, then – you guessed it!—the next scan would have to examine 10 million plus one files.
A slightly better approach is to check the modification file times of the files and then only search the contents of those files that have been updated since the last scan. It’s the same strategy that an incremental backup system would use — that is, check the modification times and other metadata that’s associated with the file.
Even so, this is a resource intensive process — CPU and disk accesses — and with large corporate file systems in the tens and hundreds of terabyte range, it may not be very practical. The system would still have to look at at every file’s last access time metadata.
A better idea is to use true incremental scanning. This means that you don’t check each file’s modification date to see if it has changed.
Instead, this optimized technique works from a known list of changed file objects provided by the underlying OS. In other words, if you can track every file change event—information that an OS kernel has access to – then you can generate a list of just the file objects that should be scanned.
This is a far better approach than a standard (but slow) crawl of the entire file system.
To accomplish this, you’ll need access to the core metadata contained in the file system — minimally, file modification time stamps but ideally other fields related to user access and group access ids.
Solutions and conclusions
Is there a way to do true incremental scanning as part of a data-centric risk assessment program?
Welcome to the Varonis IDU (Intelligent Data Use) Classification Framework!
Here’s how it works.
The Classification Framework is built on a core Varonis technology, the Varonis Metadata Framework. We have access to internal OS metadata and can track all file and directory events – creation, update, copy, move, and deletes. This is not just another app running on top of the operating system, instead the Metadata Framework integrates at a low-level with the OS while not adding any appreciable overhead.
With this metadata, the Classification Framework can now perform speedy incremental scanning. The Framework is scanning on a small subset of file objects — just the ones that have been changed or newly created—thereby allowing it to jump directly to these files rather than having to scan the complete system
The Varonis IDU Classification Framework is then able to quickly classify the file content using either our own Varonis classification engine or classification metadata from a third-party source, such as RSA.
The IDU Classification Framework works with our DatAdvantage product, which uses file metadata to determine who is the true owner of the sensitive content.
Ultimately, the Varonis solution enables data owners — the managers really in charge of the content and most knowledgeable about proper access rights — to set appropriate file permissions that reduce or eliminate data exposure risk.




